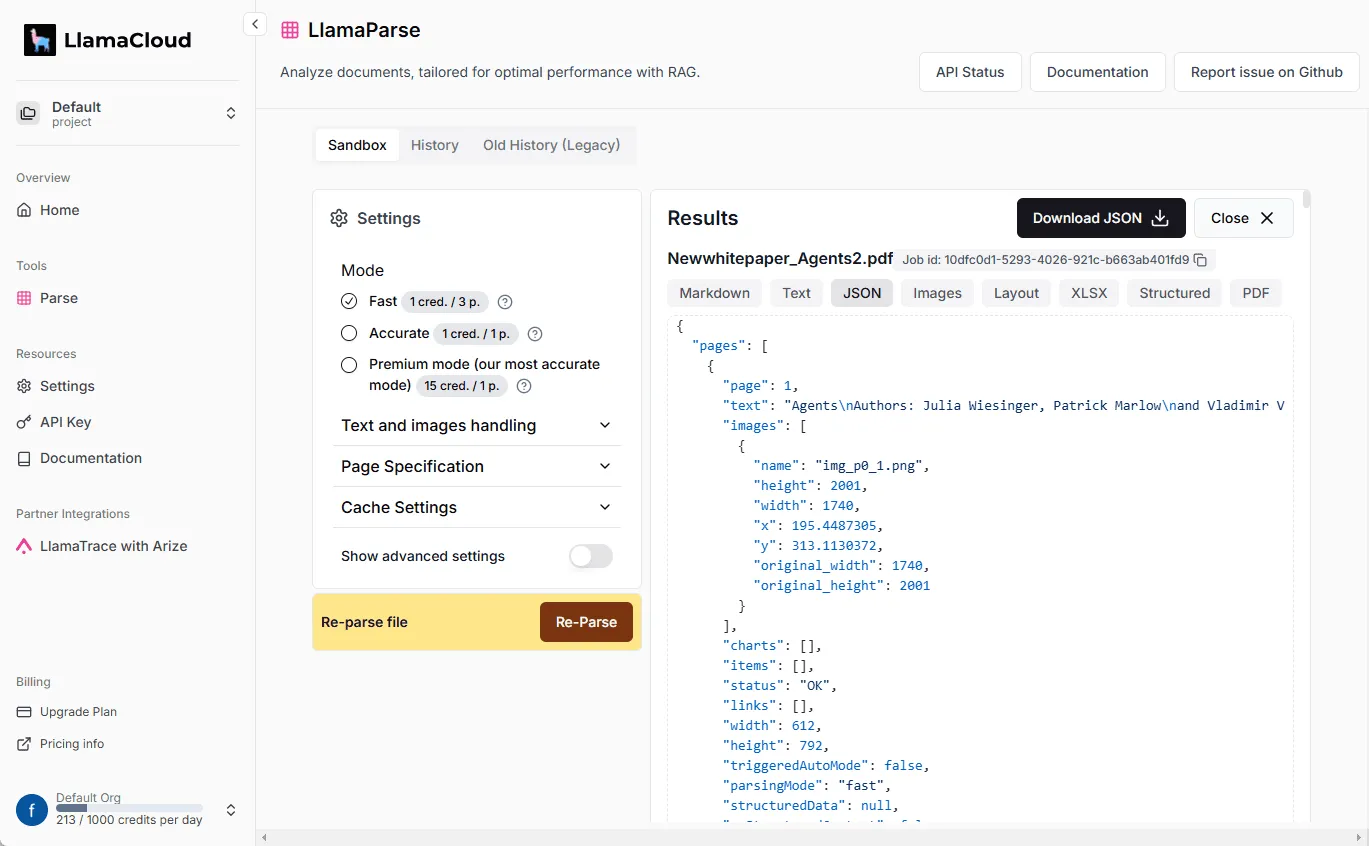
vLLM CLI
综合介绍
vLLM CLI 是一个用于部署和管理大型语言模型(LLM)的命令行工具,基于 vLLM 框架开发。它提供交互模式和命令行模式,方便用户在本地或通过 HuggingFace Hub 部署模型。工具支持 GPU 状态监控、模型自动发现和配置文件管理,适合开发者、研究人员和需要快速部署 LLM 的用户。界面直观,操作简单,支持多 GPU 优化和多种预设配置,满足不同硬件和性能需求。
功能列表
- 交互模式:通过菜单驱动的终端界面,轻松选择模型、配置参数和监控服务器。
- 命令行模式:支持自动化脚本,直接运行命令快速部署模型。
- 模型管理:自动检测本地模型,支持从 HuggingFace Hub 直接加载远程模型。
- 配置管理:提供标准、高吞吐量、MoE 优化和低内存四种预设配置文件,满足不同场景。
- 服务器监控:实时显示 GPU 使用率、服务器状态和日志流。
- 系统信息:展示 GPU、内存、CUDA 兼容性等硬件信息。
- 日志查看:当服务器启动失败时,可查看完整日志进行错误排查。
使用帮助
安装流程
vLLM CLI 支持通过 PyPI 安装或从源码构建,需满足以下条件:
- Python 3.8 或更高版本
- 支持 CUDA 的 NVIDIA GPU(目前仅支持 NVIDIA GPU)
- 已安装 vLLM 包
从 PyPI 安装
运行以下命令快速安装:
pip install vllm-cli
安装完成后,可直接使用 vllm-cli 命令。
从源码构建
- 克隆代码库:
git clone https://github.com/Chen-zexi/vllm-cli.git
cd vllm-cli
- 创建并激活 Conda 环境:
conda create -n vllm-cli python=3.11
conda activate vllm-cli
- 安装依赖:
pip install -r requirements.txt
pip install hf-model-tool
- 开发模式安装:
pip install -e .
使用方法
交互模式
运行以下命令启动交互模式:
vllm-cli
进入后,界面显示菜单,包含以下功能:
- 模型选择:列出本地模型或从 HuggingFace Hub 选择模型,支持自动下载。
- 快速部署:使用上次成功配置快速启动服务器。
- 自定义配置:调整 vLLM 参数(如量化方式、并行度),通过分类界面设置。
- 服务器监控:查看 GPU 使用率、内存占用和实时日志。
- 系统信息:显示 GPU 型号、CUDA 版本和依赖信息。
命令行模式
命令行模式适合自动化脚本或快速操作,常用命令包括:
- 启动模型服务:
vllm-cli serve MODEL_NAME
示例:vllm-cli serve facebook/opt-125m
- 使用预设配置文件:
vllm-cli serve MODEL_NAME --profile standard
- 自定义参数启动:
vllm-cli serve MODEL_NAME --quantization awq --tensor-parallel-size 2
- 查看可用模型:
vllm-cli models
- 查看系统信息:
vllm-cli info
- 检查运行中的服务器:
vllm-cli status
- 停止指定服务器:
vllm-cli stop --port 8000
配置管理
vLLM CLI 提供灵活的配置系统,配置文件存储在:
- 主配置:
~/.config/vllm-cli/config.yaml - 用户配置文件:
~/.config/vllm-cli/user_profiles.json - 缓存文件:
~/.config/vllm-cli/cache.json
内置配置文件
工具提供四种预设配置文件,自动检测多 GPU 并设置张量并行:
- standard:默认配置,适合大多数模型和硬件。
- moe_optimized:针对混合专家(MoE)模型优化,启用专家并行。
- high_throughput:高吞吐量配置,设置最大模型长度为 8192,GPU 内存利用率为 95%,启用前缀缓存等功能。
- low_memory:低内存配置,使用量化(如 bitsandbytes)和保守内存设置,适合资源受限环境。
自定义配置
在交互模式中,可通过界面调整参数,如模型长度、量化方式和并行度。配置文件以 JSON 格式保存,示例:
{
"max_model_len": 4096,
"gpu_memory_utilization": 0.70,
"quantization": "bitsandbytes"
}
错误处理
启动服务器失败时,工具会显示错误提示并提供日志查看选项。日志文件存储在用户配置目录,方便排查问题。
系统要求
- 操作系统:Linux
- 硬件:NVIDIA GPU(需 CUDA 支持)
- 依赖:vLLM、PyTorch(带 CUDA 支持)、hf-model-tool、Rich、Inquirer、psutil、PyYAML
环境变量
VLLM_CLI_ASCII_BOXES:启用 ASCII 字符界面,适配兼容性。VLLM_CLI_LOG_LEVEL:设置日志级别(如 DEBUG、INFO)。
应用场景
- AI 模型开发开发者可通过 vLLM CLI 快速部署和测试大型语言模型,调整参数以优化性能,适合研究新模型或验证模型效果。
- 自动化工作流使用命令行模式,集成到 CI/CD 管道或脚本中,自动化部署模型服务,提升开发效率。
- 教育与研究研究人员可利用交互模式探索模型性能,查看 GPU 状态和实时日志,适合教学或实验场景。
- 低资源环境部署在内存有限的设备上,使用低内存配置部署模型,适合边缘设备或小型服务器。
QA
- vLLM CLI 支持哪些操作系统?目前仅支持 Linux 系统,且需 NVIDIA GPU 和 CUDA 支持。
- 如何从 HuggingFace Hub 加载模型?在交互模式中选择“远程模型”,工具会列出 HuggingFace Hub 的模型并自动下载。
- 如何查看服务器运行状态?使用
vllm-cli status命令或交互模式的监控界面,查看 GPU 使用率和服务器状态。 - 启动失败怎么办?工具会提示错误并提供日志查看选项,检查
~/.config/vllm-cli/目录下的日志文件。 - 是否支持 AMD GPU?目前仅支持 NVIDIA GPU,欢迎提交 PR 扩展支持。